
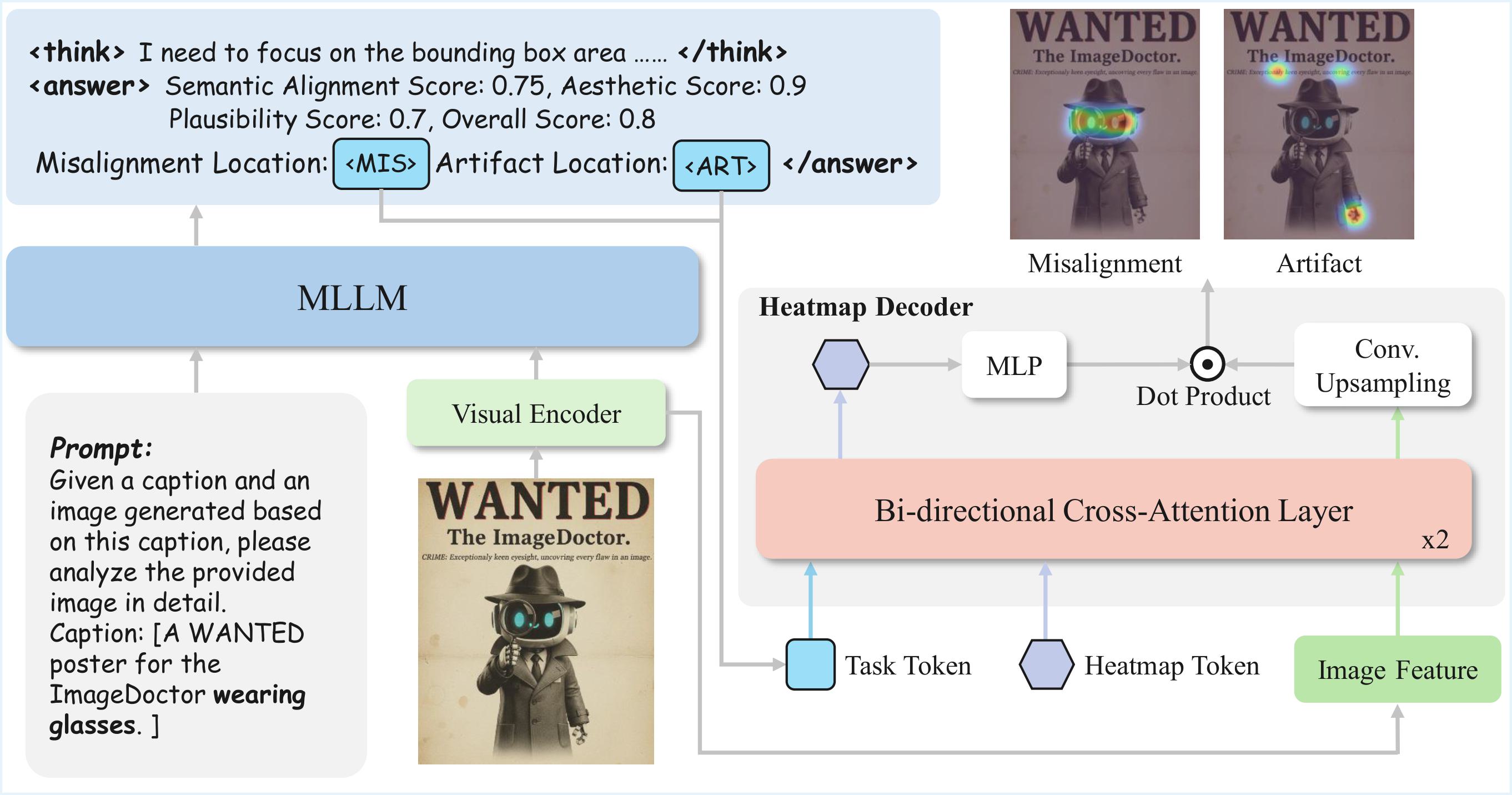
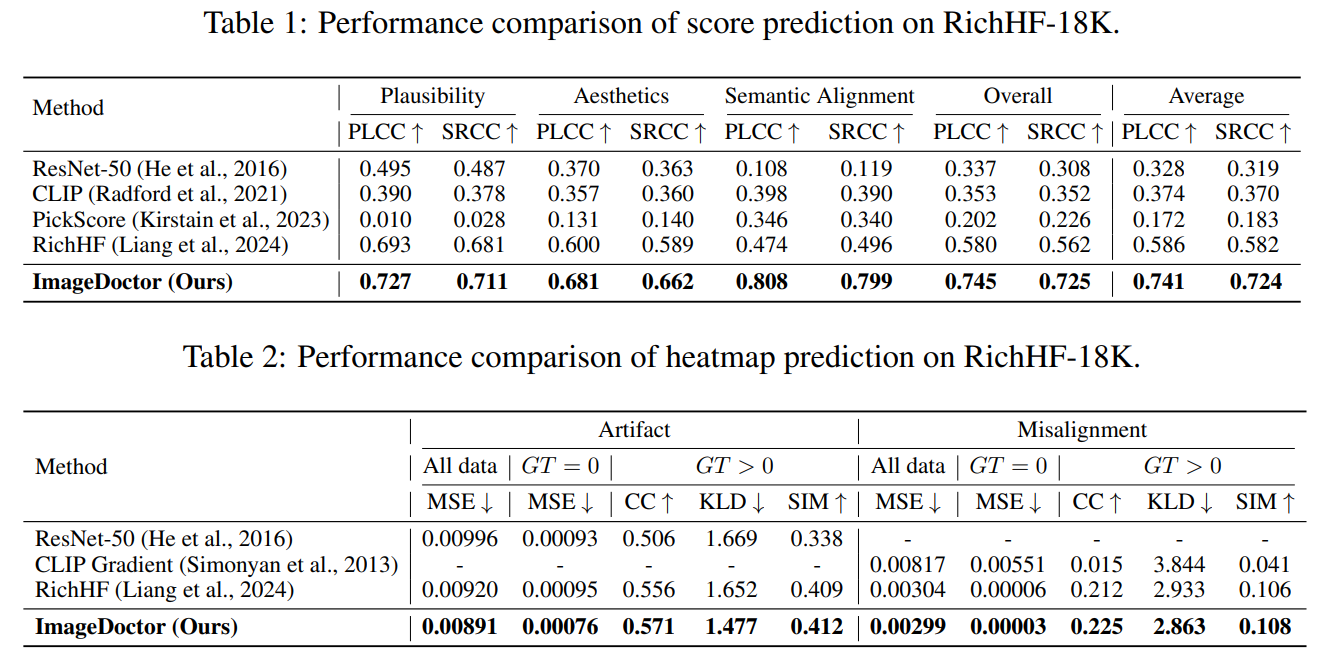



We employ ImageDoctor as a verifier to distinguish subtle differences among generated images and reliably select the best candidate. It consistently favors images that align more closely with the prompt, often preferring those with more realistic and coherent details.
